使用ModelSerializer简化代码
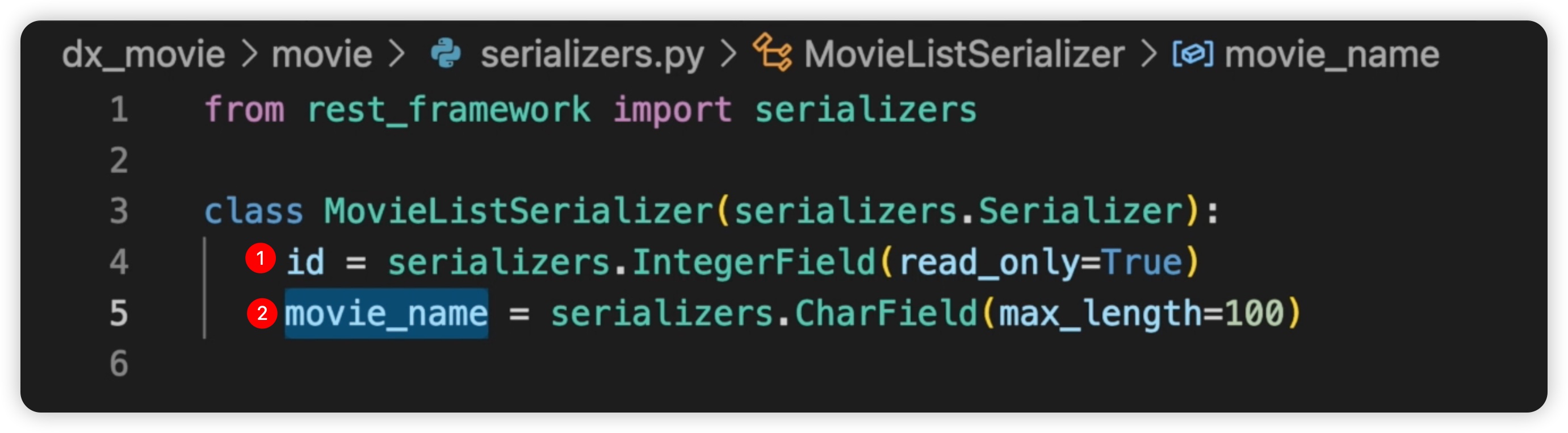
前面我们创建了一个电影列表的序列化器。在��这个简单的序列化器中,我们实现了相同的访问功能。然而,在这里,我们只写了两个字段。由于字段比较多,如果一个一个写的话,会非常麻烦。那么,有没有更加简单的方式呢?答案肯定是肯定的。因为我们能想到的问题,Django REST framework(drf)早已经为我们考虑过了。我们可以仔细观察一下这里的ID和电影名称。这和我们在创建模型时非常类似。如下图所示:
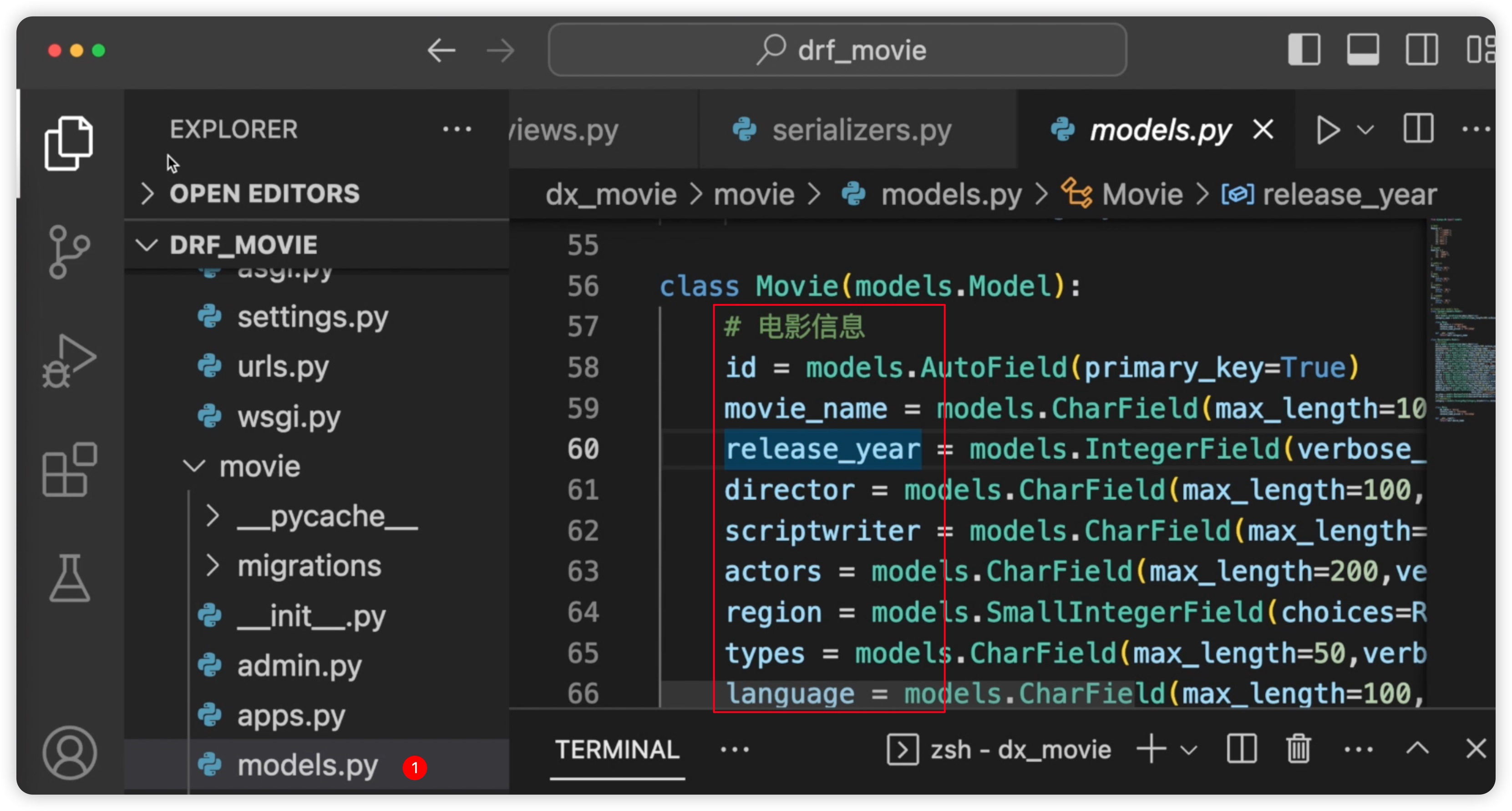
我们找到我们movie文件夹下面的models.py文件中,在这里我们同样创建了ID、电影名称等多个字段。如下图所示:
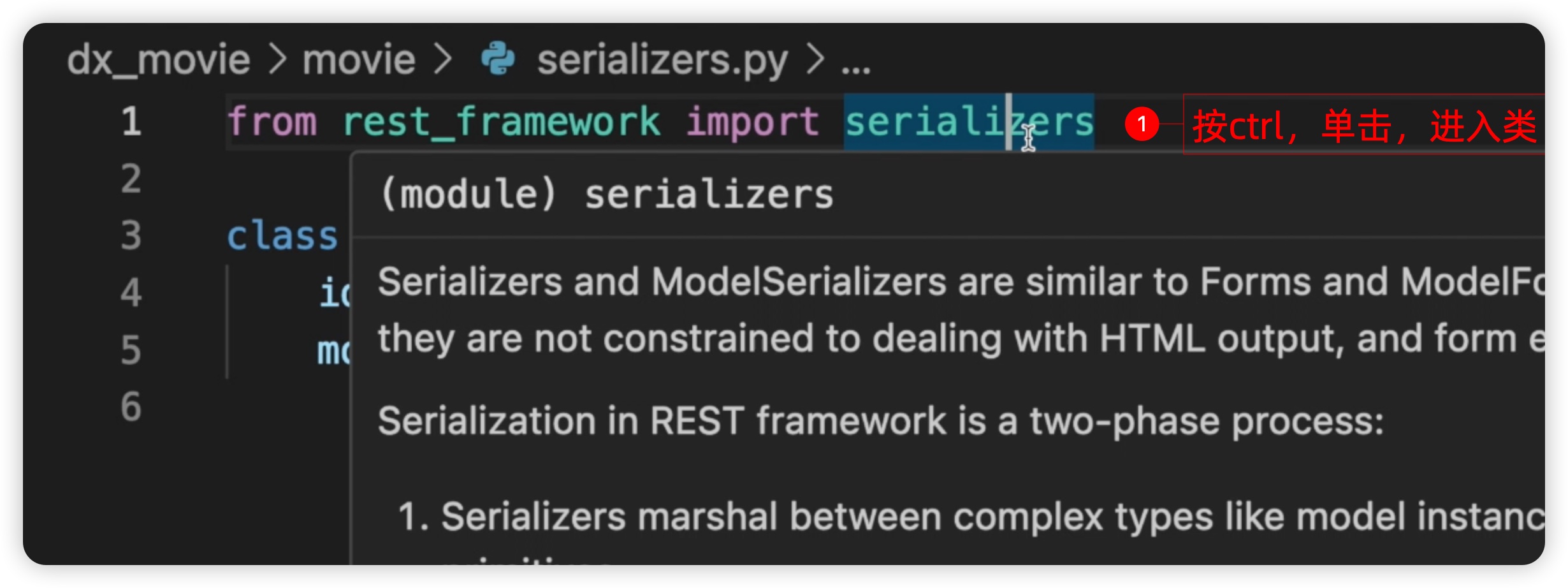
那么我们是否可以直接利用模型中的字段呢?答案是肯定的。我们可以看一下Model Serializer是如何实现的。我们在movie/serializers.py文件中,我们可以进入到这个Model Serializer的类,按一下CTRL键,然后点击,这样就可以进入到源码了。如下图所示:
这个代码比较长,我们可以直接搜索一下,搜索model serializers。这里就是源码中定义的一个Model Serializer类。如下图所示:
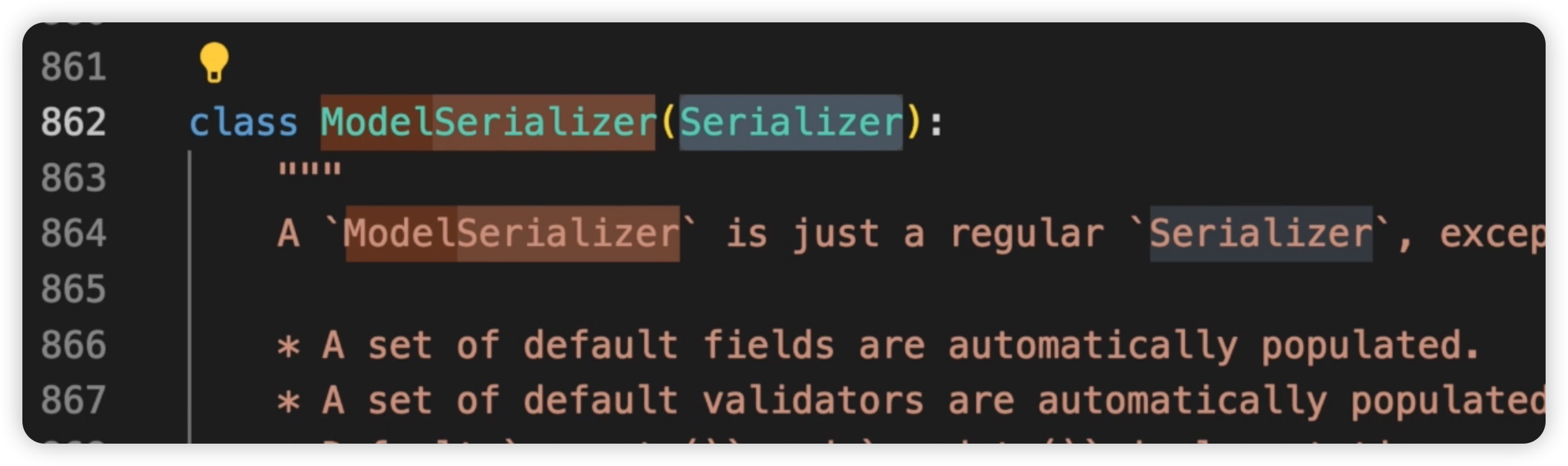
Model Serializer这个类的作用就是可以将模型中定义的字段类型转化为serializer中的字段类型。并且在内部进行了模型字段到序列化器字段的映射。通过使用ModelSerializer类,我们可以省去一个个定义字段的步��骤,让它自动匹配模型中的字段。这样可以使我们的代码更简洁,不需要手动定义每个字段的序列化过程。如下图所示:
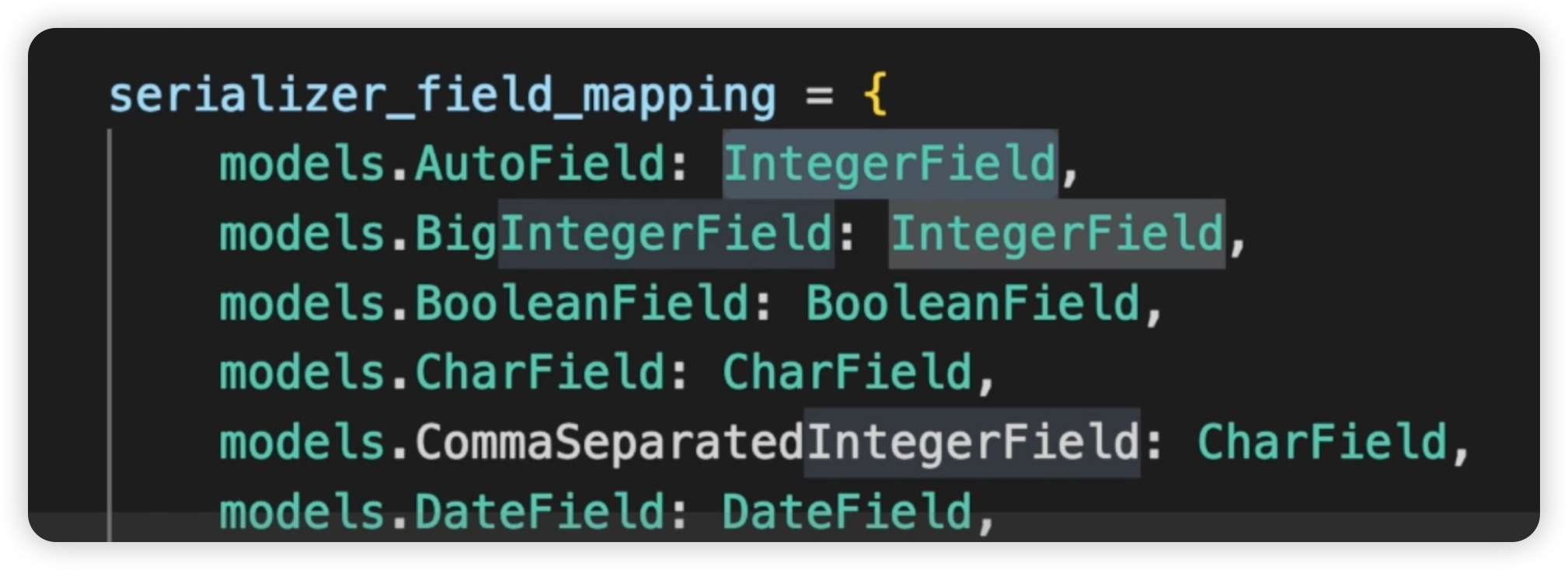
因此,我们直接修改一下模型,在movie/serializers.py文件中我们修改代码让MovieListSerializer继承的是Model Serializer类。使用这个类以后,让它自动从模型中去匹配。代码如下:
# 从rest_framework模块中导入序列化器基类
from rest_framework import serializers
# 从movie.models模块中导入Movie模型
from movie.models import Movie
# 定义电影序列化器
class MovieSerializer(serializers.ModelSerializer):
class Meta:
# 指定序列化器要使用的模型
model = Movie
# 指定要序列化的字段,'__all__'表示序列化所有字段
fields = '__all__'
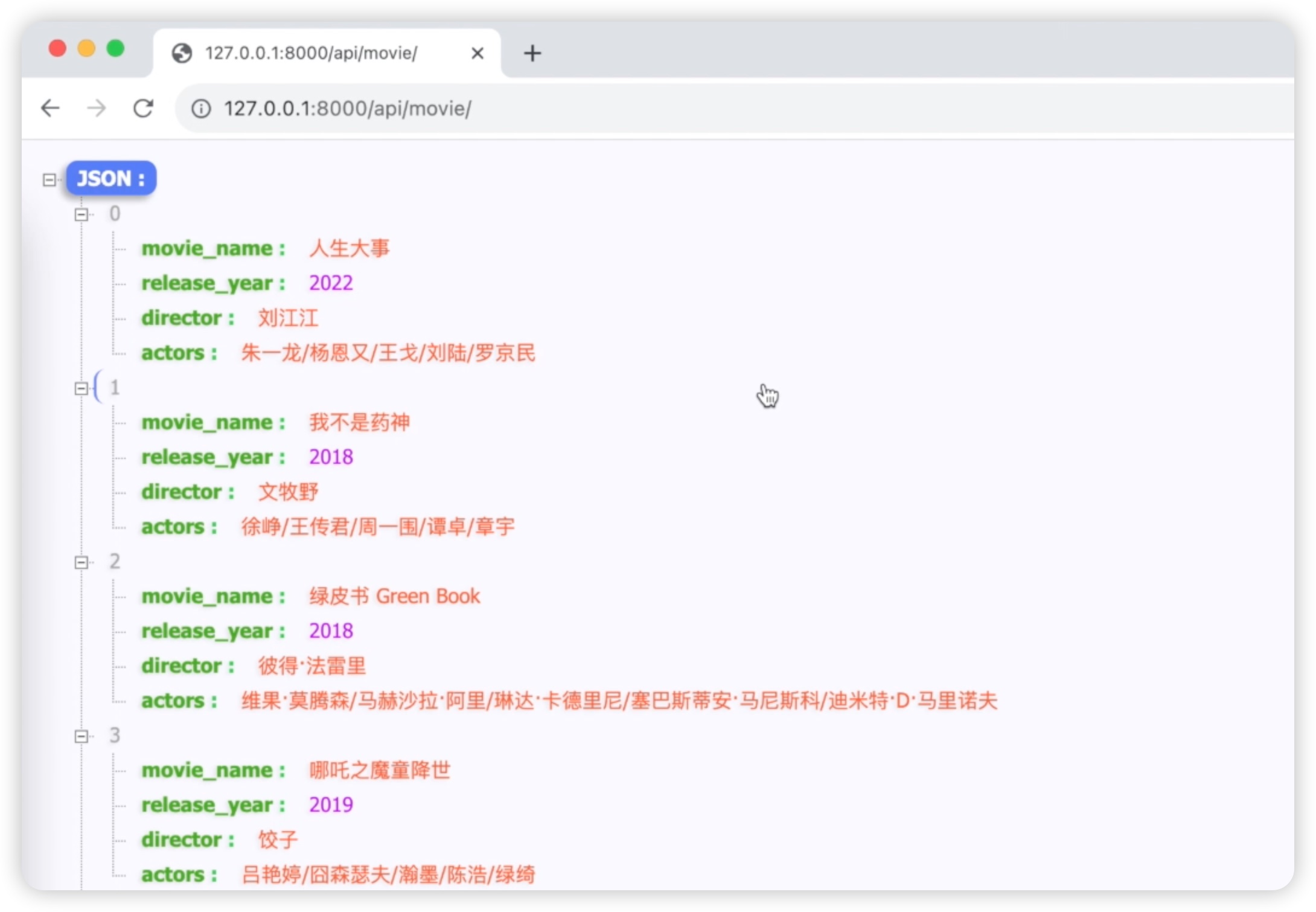
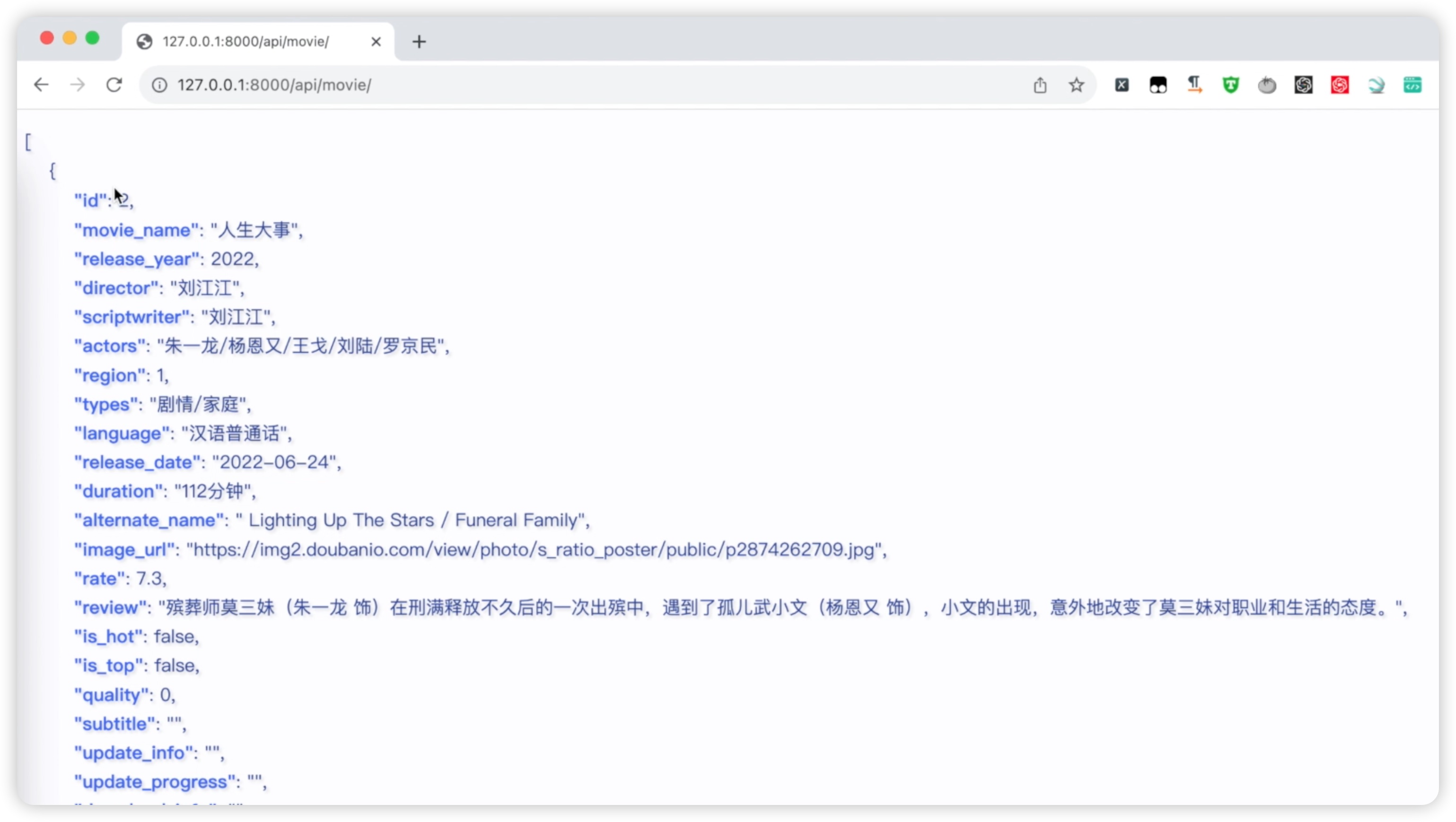
这样的话,我们的接口就会显示全部字段。刷新我们的浏览器页面,如下图所示:
如果我们只选择我们需要的字段,可以使用一个列表,将所有需要序列化的字段全部填写到这里。代码修改如下:
# 从rest_framework模块中导入序列化器基类
from rest_framework import serializers
# 从movie.models模块中导入Movie模型
from movie.models import Movie
# 定义电影序列化器
class MovieSerializer(serializers.ModelSerializer):
class Meta:
# 指定序列化器要使用的模型
model = Movie
# 指定要序列化的字段
fields = ['movie_name', "release_year', 'director', 'actors']
再刷新我们的浏览器页面,这次只显示4个字段,如下图所示: